RAG, CAG or LLMAR?
RAG: Retrieval-Augmented Generation
No introduction needed: everybody is talking about RAG these days to overcome the “issues” of language generation by an LLM. Question that we want to address here is the following: can RAG be the answer or even a replacement for search?
LLM’s are great in understanding language and what we intent with our use of language, but lack the correctness of information. Hence the R in RAG: we retrieve a bulk load of information via search and provide it to the LLM to process the information using his language skillsets. So, in essence, we do traditional search (keyword or vector) and process it with AI (hance, we can check the box “AI” from the bucket list). A great, but quite compute intensive, way to deal with the processing of information!
Important consequence of RAG is that the quality of the “information” part of the result will be determined by the quality of the R in RAG. And, you might have guessed, we can help you improve your information retrieval!
CAG: Cache-Augmented Generation
CAG = RAG where the retrieval part is simply a cache of the whole data corpus that is made available to the LLM to do its magic.
With the growth of the number of tokens in the context windows of (modern) LLM’s, people might be tempted to skip/neglect the retrieval part of the RAG and just provide all the data to the LLM for it to sort out the information need (and assuming that there is no problem in sharing all your data of course).
This might be an appealing thought. However, currently only suitable for use cases where 1) the corpus is limited to fit in the context window and 2) the number of queries is low. Not sure whether this will ever be considered affordable in the long run…
LLMAR: LLM Augmented Retrieval
Our traditional approach (does this sound “ugly”?) of dealing with information retrieval: indexing and querying pipelines. The 2 schemas below, look very much like the traditional indexing and querying pipelines that we have been using for decades.
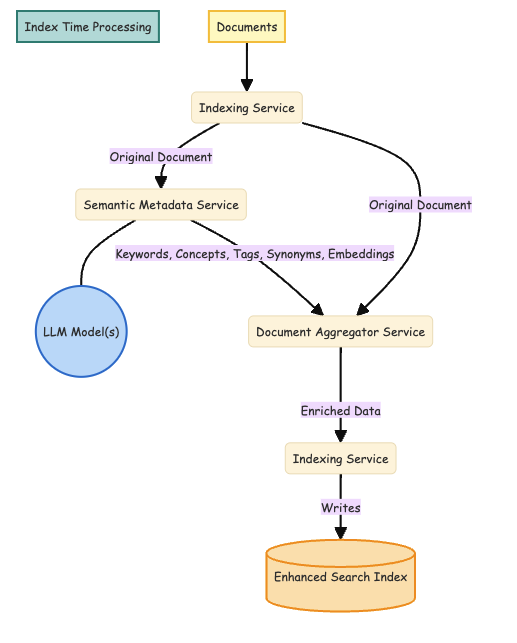
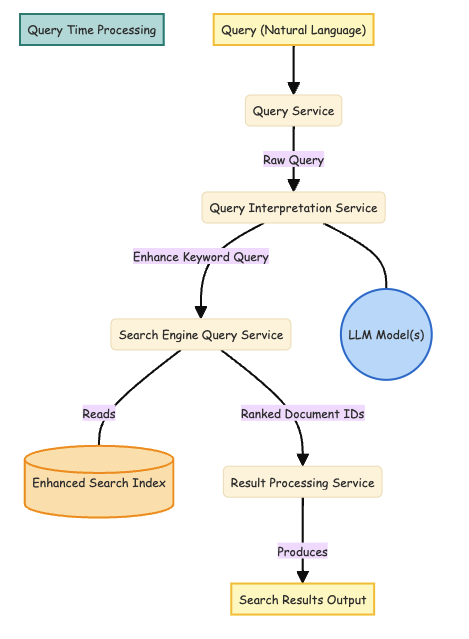
In this approach, we increase the quality of our search by manipulating and enriching data and user queries both at index time and at query time. And a major problem to solve in both these pipelines is handling “language”.
Today, we’re fortunate to be able to rely on LLM’s that are very good at dealing with this language handling problem: LLM’s are the universal tools that help us to overcome this problem. And because of the incredible capabilities of LLM’s in NLP, we have now taken huge steps to simplify these tasks.
By augmenting retrieval with LLMs, LLMAR moves beyond simple keyword matching or adjacant vector neighborhood to understand context and intent. It leverages the strengths of traditional indexing while adding a tuneable layer of semantic intelligence, resulting in significantly more relevant and accurate search results from your large-scale document repositories.
On top of that, the usual tools that are deployed to direct the search results towards fulfilling the business goals are kept in tact. That might be the most important argument to keep focusing on this approach.
By the way, the term LLMAR might sound compelling these days. It is also referred to as “reversed RAG” or “GAR”. But, to be clear, there is nothing wrong with using good old “IR” as the term to refer to the system that enables the search process.
Curious to learn more? Feel free to reach out using the contact form here!
